索引構成表やクラスタは、索引のように、データベース検索のパフォーマンスを向上させるためにOracleから提供されている機能である。
索引構成表やクラスタを使用すれば、行の格納方法を制御できる。
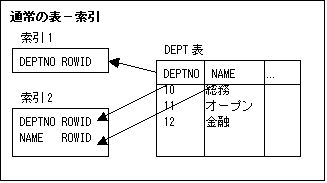
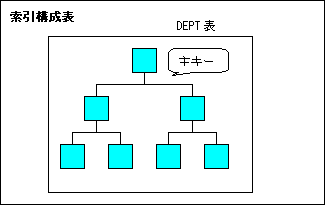
索引構成表は索引ではなく、B*Tree構造に基づいてデータが格納された「表」である。
- データは表の主キーに基づいてソートされている。(通常の表では挿入した順)
- ROWIDは持たない。
- ROWIDの代わりに、非キー列がリーフエントリに格納されている。
そのため、表とは別に索引用の領域を必要としないため、必要なディスクスペースが減るという利点がある。
また、主キーでソートされているため、主キーによる操作は高速に行なうことができる。●通常の表と索引構成表の比較
通常の表 索引構成表 ROWIDで行を一意に識別する 主キーで行を一意に識別する ROWIDを持つ ROWIDを持たない 2次索引(主キー以外の索引)を持つことができる 2次索引を持つことができない(ROWIDを持たないため) 全表走査を行なった場合、ROWIDの順序で行が戻される 全表走査を行なった場合、主キー順で行が戻される 一意制約を宣言することができる 一意制約以外の制約しか宣言できない 分散トランザクション、レプリケーション、パーティション化をサポートしている 分散トランザクション、レプリケーション、パーティション化をサポートしていない
索引構成表は、CREATE TABLE文にORGANIZATION INDEX句を指定して作成する。
主キーは必ず指定する必要がある。
CREATE TABLE [スキーマ名.]索引構成表名
(列 データ型[, 列 データ型...])
ORGANIZATION INDEX
[TABLESPACE 表領域名][PCTFREE 空き領域割合]
[INITRANS トランザクションスロット初期数]
[MAXTRANS トランザクションスロット最大数]
[STORAGE ([INITIAL 初期エクステントサイズ [K | M] ]
[NEXT 増分エクステントサイズ [K | M] ]
[MINEXTENTS 作成時エクステント数]
[MAXEXTENTS {最大エクステント数 | UNLIMITED}
[PCTINCREASE エクステントサイズ拡大率 ])[PCTTHRESHOLD 領域の割合
[INCLUDING 列 ] ]
[OVERFLOW セグメント格納方法など]
]:
例(pk_deptが主キー)
CREATE TABLE DEPT
(DEPTNO NUMBER(2),
NAME CHAR(20),
LOC VARCHER2(50),
MANAGER_NAME VARCHAR2(50),
CONSTRAINT pk_dept PRIMARY KEY (DEPTNO) )ORGANIZATION INDEX
TABLESPACE USR2
PCTTHRESHOLD 20
OVERFLOW TABLESPACE USR3;
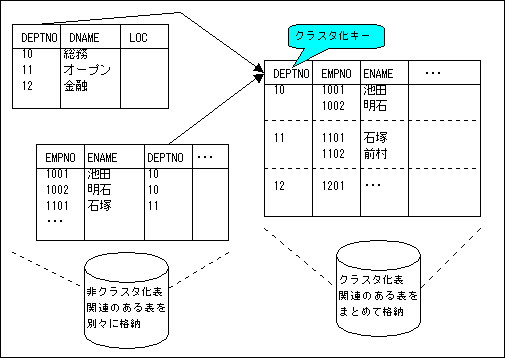
関連する列に基づいて、2つ以上の表を結合して、一つのデータブロックに格納したものである。
- データは特定の列の値(クラスタキー)に基づいて、複数の表が分類結合されて同じデータブロックに格納されている。(通常の表では挿入した順)
- ランダムアクセスは高速になるが、全表走査は遅くなる傾向がある。
- クラスタキー列を更新すると、その行が別の場所に再配置されるため、更新パフォーマンスは悪くなる。
- クラスタキーは、1つ以上の列を指定することができる。
- クラスタに格納する全ての表にクラスタキーに対応する列が必要。
- クラスタ内の表に、クラスタキー以外の列を主キーとして設定することは可能。
●索引クラスタとハッシュクラスタ
データの分類の仕方によって、クラスタは索引クラスタとハッシュクラスタに分類される。
索引クラスタ
ハッシュクラスタ
複数の表から共通のクラスタキーの列値をもった行がまとめられて、一つの領域(クラスタブロック)に格納する。 ハッシュ関数にクラスタキーの列値を渡し、その値にしたがって複数の表を分類して、クラスタブロックに格納する。 結合処理で同時に使用されることの多い複数の表を、WHERE句によく指定される列を クラスタキーにしてクラスタ化すればパフォーマンスが向上する。 検索時にクラスタキーの列値にハッシュ関数を適用し、データの格納場所をすぐに見つけられるため、 大量データの中から1件のデータを検索するような処理でパフォーマンスが向上する。
クラスタは、CREATE CLUSTER文でクラスタを定義したあと、CREATE TABLE文にCLUSTER句を指定して表をクラスタ内に格納する。
●クラスタを定義し、複数の表を索引クラスタ内に格納する例
CREATE CLUSTER CL_EMP (deptno number(2))
SIZE 2048
TABLESPACE USR2
STORAGE (INITILAL 100M NEXT 100K PCTINCREASE 0);
CREATE TABLE DEPT (deptno number(2), dname verchar2(12), loc varchar2(12))
CLUSTER CL_EMP(deptno);
CREATE TABLE EMP (empno number(4) not NULL, ename char(10), job char(9)
, hiredate date, sal number(7,2), deptno number(2))
CLUSTER CL_EMP(deptno);
CREATE INDEX CL_EMP_IX ON CLUSTER CL_EMP; <--最後にクラスタ索引を作成※索引クラスタの場合、クラスタ索引を作成しないとデータの挿入を含む全てのアクセスができないため、最後にCREATE INDEX文を使って索引を設定する必要がある。
※SIZE句で指定するクラスタブロックサイズは、各クラスタキーに属するデータ量の平均値を見積もって決定する。SIZE句で指定できる最大値およびデフォルト値は、ブロックサイズ。
●ハッシュクラスタの作成
CREATE CLUSTER HASH_EMP (empno number(4))
SIZE 1024
HASHKEY 3000
TABLESPACE USR2
STORAGE (INITILAL 100M NEXT 100K PCTINCREASE 0);
CREATE TABLE EMP (empno number(4) not NULL, ename char(10), job char(9)
, hiredate date, sal number(7,2), deptno number(2))
CLUSTER HASH_EMP(empno);※ハッシュクラスタの場合、HASHKEY句を使ってハッシュキーの数を指定する。このとき、一つのキーに対応する行数を決定し、その行数×行サイズによってクラスタブロックサイズを決定する必要がある。